Welcome
Category Archives: Programming
Bangla Pi: Is Affordable Computing the Silver Bullet to Development?
(A version of this article was published at the Conference for Asian Countries on Digital Government)
“Look, this cat is moving!”, Duti, a 12 years old girl from Hajipur girls’ school exclaimed. Her eyes fixated on the 10 inch LCD screen of a bizarre device with wooden frame labeled “Bangla Pi” that clearly was concealing a prototype. And standing five feet away from her, the incredible feat to enable a girl from the one of the most remote villages of Bangladesh to program a computer struck me. This village girl just animated a cat with the programming language scratch, developed in the MIT Media Lab.

To understand the story behind this rather extraordinary scene, we have to jump back six months in time to my dorm room at Harvard. One day, while working with raspberry pi, a credit card sized computer that is sold for 35 USD, the idea of using a similar hardware architecture as a medium to affordable computing and access to information crossed my mind. As I dug deeper, I realized how far the semiconductor industry has come. By Moore’s law, we have already seen how computing power has doubled every 18 months over the past few decades. As a result, the cellphone in my pocket has a processor with more computing power than the computers that launched Apollo mission to the Moon!
The basic idea behind this affordable computing tool was to use the smart-phone processors (which can be bought for as little as 3 USD in the chinese market). Using this processors along with open source operating systems such as Debian or Ubuntu, we can simulate a desktop computer like experience. I used the cheapest processors and put it together with LCD panels to make a device that can do everything a typical computer can do, but for a much lower price. I named this device Bangla Pi.
I went back to Bangladesh during my winter break of senior year (2015) on a fellowship from Harvard South Asia Institute and made 20 of these prototypes. I bought electronics parts from China and spent a long week making those devices. Because I did not not have access to a 3D printer (would not be cost effective anyways), I just went to local photo frame makers to custom build wooden casing for them. These bizarre devices could function exactly the same way as typical desktop/laptop computers and had USB ports for a mouse and a keyboard. It was also possible (after a lot of hacking) to connect wifi modules to the devices to support connectivity. It cost me ~65USD to make each of these devices and the LCD panels were the most expensive parts (~40 USD each). However, talking to some of the chinese manufacturers I found that at scale these price can be much lower.

With these devices, I ran a few pilot project in Dhaka and a few very remote villages in Bangladesh. The results I found were amazing–the students (who were between 12-18 years old high school students) seemed to pick up these skills very, very quickly. I was amazed how some of them, without having used computer before, made computer games with the programming language Scratch, an interactive, easy to use, graphical programming language that enables young students to program by moving small code blocks. The most important lesson that I learned from this experience was that we can enable natural learning with similar devices and with connectivity we can empower students learn anything they wanted to learn about.
Now that we have a very affordable computing platform that promises to deliver connectivity and computing power, should we just distribute these devices en-masse? While I truly believe in the potential of Bangla Pi and similar affordable computing platforms, I think answer is more complex than a simple yes or no. Although it takes a bit of naiveté and a leap of faith to do something as crazy as connecting the world where many other challenges are presumably of higher importance today, I would argue that this naiveté even part of highly acclaimed and widely distributed devices such as one laptop per child (OLPC) by MIT Media Lab founder Professor Nicholas Negroponte. While his idea of sub 100 dollar computer was bold, the most important thing OLPC missed missed were the right context and the ability to emulate an operating system similar to a standard desktop PC. First of all, OLPC lacked a clear goal as an use case, whereas for Bangla the goal was clear–enable learning how to operate computers and incorporate it to a standard curricula.
Another important aspect that many of the technopreneurs forget is the importance of training and customer service. We might deliver computers to every school (with enough funding) but if we do not train the teachers and cannot make sure that the devices will be functional after a few months, then we are probably introducing an overhead instead of helping the educators. For this very reason, we designed Bangla Pi as modular units. There are five different units in Bangla Pi–processing unit, power unit, display units, input unit (mouse/keyboard) and each of these individual units (except the display, which is fairly durable) costs under 10 USD and is very easy to replace in a plug and play fashion. So we can create a 10% redundancy with spare parts (example–in a school with hundred computers) and easily make sure that all of the units are working fully.
I have studied many literatures and books on the topic of computing in developing countries. One that truly grabbed my attention was The Geek Heresy by Kentaro Toyama, a fellow Harvard alum and a former Microsoft Research fellow in India (and current professor at the University of Michigan). In his book, he brought up many important points regarding how many of these silver bullet solutions for development with technology have failed. And from his experience through working in India at Microsoft research, he also explains the nature of some of the projects that truly succeeded. While it is beyond the scope of this article, I would like to talk about the main point of the book which is that technology primarily amplifies human forces, but if there is no force existent today no amount of technology will help. The same philosophy was apparent in Microsoft’s founder Bill Gates’ book The Road Ahead, in which he said “The first rule of any technology used in business is that automation applied to an efficient operation will magnify the efficiency. [...] Automation applied to an inefficient operation will magnify the inefficiency”. Therefore, the primary point that we need to address before we just go ahead a make all the schools digital is that we need to make sure our human force (i.e. the teachers) are at a state where they can take part in this amplification process.
Now the question stands—in the context of Bangladesh and similar developing countries, how can we leverage the technologies such as Bangla Pi to amplify the human capabilities? At the risk of sounding cliché, we need to ask how we can empower the people with these technologies and make sure they have access to the information and services that they need to improve their quality of life. I personally believe that the possibilities are endless. Let me start with a few possible key game changers:
1. Improving education with human augmented technology: We could develop a centralized digital pedagogical system where typical hour long teaching method would be augmented by a 15 minutes of visual contents. This could both take a bit of teaching burden off of the teachers’ shoulders and make learning much more interesting for the students.
2. Access to better health information and services: We could empower the current network of health workers to be able to connect with the people in the villages better via technology products such as Bangla Pi. Moreover, they would be able to direct the people on where to find the best healthcare by providing information via these devices.
3. Marketplace for the farmers: Without getting into details, a major shift in the current marketplace could be achieved if we could eliminate the information asymmetry that exists in the agri-marketplace. This information asymmetry only helps the middlemen and harms the farmers and end consumers.
For all these problems to be solved, we need to acknowledge the existing solutions and see how technology based solutions using connected devices such as Bangla Pi could help us solve these problems by amplifying the existing human efforts. While a very strong supporter and believer of technology, I do not think that technology alone can solve all our problems (maybe in 20 years we will have strong AI (artificial intelligence) in place and it will be a different story, but not today). However, technology augmented with human power can amplify the efficiency of the human force by manifold and as a result can fundamentally change the way billions of poor people live. Just imagine a village in Bangladesh, where the farmers can get information from the agriculture within a few seconds and can get health information when his wife is pregnant. Imagine a world where his kids go to school and get education augmented by thought provoking visuals and proven pedagogical guidelines. Imagine a world where that very farmer can auction his crops at the best price in a marketplace where information asymmetry does not exist. Imagine a world where the power of the government is distributed to the masses because everyone is well informed. That future, enabled with technology and connectivity to vastly amplify and truly empower the human efforts is the future I dream of everyday.
Project Bangla Pi: Why I Care about Affordable Computing
It is ironic that similar to the way computers understand the world with compiled instructions in binaries (0s and 1s), they have divided the world into a binary group system– the group that knows how to use computers and the one that does not.
Most of the supporters of computer education these days start their pitch with teaching everyone coding and claiming that everyone will be computer scientists. While I would love that future, I feel that this pitch is coming from a first world perspective where most of the kids already owns an expensive computer and know about computers and smartphones from an early age. With this we are majorly discounting the rest of the world, where many kids have never seen computers.

Currently the world literacy rate is 84.1% (2013), but the digital literacy rate is much lower than that. With more and more computers being used every day from tasks as simples as writing emails or applying for jobs over internet to more complex tasks such as writing programs or using computers in factories, I don’t think I need to convince anyone that we need to teach young kids how to use computers. These basic computer skills are becoming as important as learning how to read and write. For that purpose we need computers accessible to all kids.
There is no doubt that the world needs more quality educational materials. Khan Academy clearly showed us how we can empower individual students if we just give them access to quality educational contents. The kids can learn themselves. Especially in many parts of the world getting a quality education is hard because of the lack of good teachers. While I don’t believe that MOOCs (online video lectures) can be as effective as direct classroom education and solve all of our problems, I believe augmenting classroom study contents could be a great use. For example, when a kid learns about history we can reinforce the learning experience with some multimedia contents. I believe flipped classroom model could be hugely successful if we can find a channel to deliver those contents to the students.

Finally I’d get back to the coding part. The kids who are already using computer for years, they should really learn to code or understand coding. They might not need to write thousands of lines of codes in future, but in this age of machine learning and massive automation, learning to code is going to be an invaluable skill for understanding the world. For example at Harvard, less than hundred students major in computer science every year, but this year 889 Harvard students took CS50, the legendary introduction to computer science class! This clearly shows why you should learn about computer science if you are already privileged to have computers.
The reason for this long and (hopefully) obvious discussion about the necessity of computers is that if we want to solve the problems of the world through better education, using computing devices is necessary. If I use the terms of Economics, computer is not a luxury good anymore– it is a necessity good for everyone. But with the average price of a good laptop being about a thousand dollar, buying computers might be a bit hard even for some people from the first world country. Now consider the countries like Bangladesh, where the average annual income per capita is 1044 USD, buying a computer for their kids is next to impossible for most of the families.
![]()
As a naive young college student, I have been thinking about this digital divide issues for a while. Last semester, when I was playing with a raspberry pi at my dorm at Harvard, I was thinking why we cannot just use these and some cheap LCD panels to make some small computers for the young students. For those who do not know what this is, Raspberry Pi is a computer board with 900 mhz (overcloked) CPU, 512MB ram, and 8 GB disk space. Basically this is equavalent to the computing power of a mid range smartphone or tablet. But do we really need that much computing power for teaching kids? It turns out–not really.
So I decided to do this over the winter break and got 15 raspberry pi boards and imported some cheap lcd panels from China (getting them cleared from customs was hard, but that is a story left for another day!). Then I scouted all over Dhaka to find cheap peripherals such as keyboards, mouse, and micro sd cards. With all these parts and many hours of labor (plus wooden frame made by the local photo frame makers), I finished assembling 15 devices and custom built a power supply system for all of them.

While assembling these was nontrivial, making the OS ready was another challenge. I have been working on using different flavors of debian for a while, but running the OS on the ARM chip is a bit hard given the resource constraints. So I had to do a bit of modification of the debian based raspbian OS and had to make sure we have everything in the Bangla Pi OS that I distributed with the 15 prototypes. The great thing is that you can do almost anything you can do with a typical computer. While this is does not have a lot of CPU power, so far they proved them to be adequate for most of the educational purposes.
So this winter I am running three pilot projects to see what we can do with these devices. We are running these workshops in three places. One in Dhaka (where all these kids have been using computers for years), another in Pakundia, a upozilla (sub-district) in Kishoregonj, and finally one in a small village of Sylhet. I am just trying to see how all these kids with very different computer literacy level interact with computers and how we can use these devices to improve education for them. I am teaching Python programming to the students in Dhaka and for the other students I would limit it to Scratch, which is a visual programming tool developed by MIT media lab.

It would be an understatement to say that organizing these has been just difficult. Thanks to my mom, and volunteers, who have been working tirelessly to help organize these workshops and create the curriculum. Also thanks to Harvard South Asia Institute for their winter grant that enabled me to do this project.
Currently the computers cost about $85 to make, but if we could mass produce them (at least couple of thousands), it is very possible to drive down to the cost with the new technology we have in R&D. This could be a great step toward making computers accessible for all. For the poor this could be a great first computer and for the privileged ones this could be a programming sandbox.
I believe that some people are better than others in some areas because of their inherent ability to excel in that. I also believe that these talented people are fairly randomly distributed regardless of geolocation or income level. So with affordable computing for everyone if we could get rid of the digital divide and make education a level playing field for the kids from the first world to those from the third world, we would be the best talents from all over the world to solve our important problem. Then we will be one step closer to having the world we all want to live in.
CS 165 or: How I learned to stop worrying about speed and Love the column stores
This Spring 2014 semester, I took CS 165, a course on big data database systems by Professor Stratos Idreos. This course was offered after quite a few years; so there were quite a few of us interested. However, for myself it was a course that I have been waiting for a few years to take. As I am very interested in data science and related topics, how database works under the hood is one of the basic principles I need to know before I can do any large scale analytics efficiently. Especially the slide from the first lecture sums up the necessity of learning about DBs perfectly:
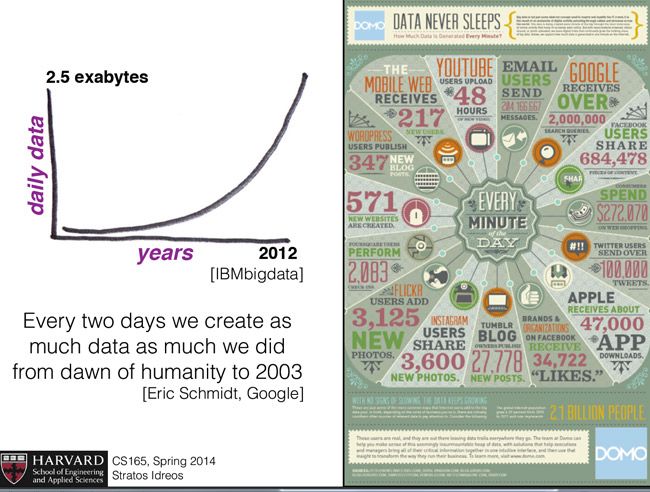
When I took the course my expectation was that this would probably be a course where we’d learn about SQL and hadoop/hive for big data. However, when I went to the office hour of Professor Idreos for the first time he said that “you don’t come to Harvard to learn about [how to code in] SQL!” So as a column storage expert, he decided to teach us about the database system in the lights of the column store paradigm.
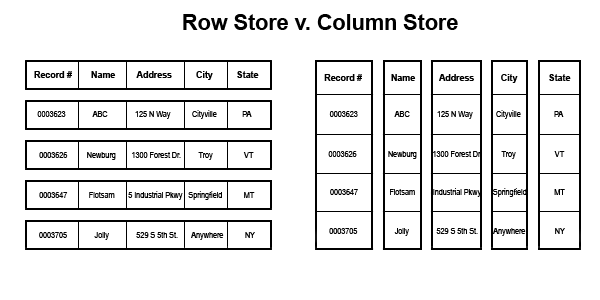
Column stores are different than the regular SQL like row stores. The store data in columns instead of rows. So when we query data the row store has to go through the whole row, whereas in column store we can just work with the specific column(s) we are interested in. This enables massive performance benefits in many cases, including scaling of the the database. I will talk about that in details in a bit.
I was excited and terrified at the same time, because having not taken any systems course (other than CS50, which does not really count) I knew that it would be really hard to make a whole working database system from scratch in C. However, I decided to stick with it. It was not easy, but I am glad I did! I feel this is one of the classes at Harvard where I learned the most. I learned how data systems work under the hood. I learned how to maintain a codebase with about 5000 lines of code. I truly learned how to use pointers and memory management. Finally I learned about low level CPU, GPU architectures and how to leverage the CPU caches to write cache conscious code. Beside these in terms I learned a lot of lessons that would pass as the big picture-take-away from the course:
Lesson 1: The real world is messy
As cliche as it might sound, the real world is too messy. It is easy to say “oh, design a database in a distributed fashion, when you have a server and client and just make the server and client send each other streams.” However, when we implement that it is a pain, to say the least. Moreover, when we get the command/data we need to parse that. Parsing strings in C is honestly no fun…or maybe I am too spoilt by Python.
Lesson 2: Sockets are neat, but painful…aargh
We have a lot of ports in our computers which we can use to communicate between computers in a network. As we had to make things distributed (i.e. many clients in a network can talk to the server) we had to make sure that the communication is actually happening. It is slightly nontrivial because at a time one computer should send message and another should listen. However, if both of them send or both of them listen, like real life, nothing productive will happen! Also the second thing I realized was that when you program your node to send it does not necessarily send the message. For example if you send 8 bytes to server, the client might not send that immediately, rather wait for more message and buffer to optimize the communication. This is a really neat and smart thing, but that means you have no control! So that kind of sucks. To get around that I had to code up a whole streaming protocol that does it correctly and that was the bane of my Spring break!
Lesson 3: B+tree…oh the black magic
If you have done any amount of CS (given you have read so far I am assuming that you have), you must have heard of the binary trees. If you had the opportunity to implement one for the first time, you probably were not the happiest person in the world. Now take that binary tree and make that more general (i.e. each node can have arbitrarily many keys). As you can probably understand, it is pretty complicated to implement a B+tree. So it was just solid 500+ lines of uncommented C code!
On the plus side, there are great advantages of B+tree. First of all, due to the structure your leafs’ keys are always sorted and you always get a balanced tree! When I saw it the first time I thought that it is black magic! However, later I realized (doing some complexity analysis) that the cost for in-memory B+tree is the same as binary tree. However, the I/O cost is significantly lower. So if you have a disk based implementation for really huge database, then it would be strictly better to use a B+tree with high order (lot of leafs).
Lesson 4: It takes a lot of hack to make something work
It is easy to throw buzzwords like distributed system, cache conscious, threaded, parallel, and so on, but it is really hard to make it work. It takes a lot of effort to make a system work and the learning curve is steep.
Especially when I was dealing with threading (to make commands from all the clients run in parallel), I realized how messed up things can get with each thread doing their own thing in parallel. And my final version is not really thread safe, but at least I understand the concept of race conditions, thread locks etc.
One hack I was particularly proud of was lazy fetching for joins. So when we make a selection and fetch, we generally have to go through different parts of the column 1+1=2 times. However, lazy fetching does not do anything in the fetch state and waits for that to happen in the join state. So I just attached the pointer to the original column (casted void!) for that and it worked really well. So in general my join would save quite a bit of work for this lazy fetching.
Lesson 5: Making things cache conscious is hard
When we have any kind of data it moves from memory (RAM) to the L1 cache of the processor which is just next to the layer of registers in a processor. So ideally you want all your data to be in L1 cache, because it takes many times more time to get data from disk/RAM compared to the L1 cache. However, L1 cache is small (something like 32KB for a core, depending on your CPU). So the best thing you can do is that to make sure when you do any computation, you don’t need to push the memory back and forth (because the CPU would push the memory back to L1 cache if it is not actively using it). So we need to make sure when we do computation with a chunk of data we do everything possible with it. This is basically the idea of cache consciousness and it is pretty hard to do this kind of optimization. So I ended up writing code like the following for loop join!

Lesson 6: Join is fascinating!
Ii is said that the most important thing invented in computer science is hashing. Although it is arguable, I know after this course that the claim is probably true. When you do join, the most naive approach is to go through each element of the second column for each element of of the first. This is clearly O(n^2). But we can do better, and sort both and do a merge sort join, which has cost O(n log n). But we can clearly do much better with hashing. We just create a hash table for the smaller column on the fly and then probe it with the elements of the bigger column and this brings it down to O(n)– the holy grail! This works really well in most cases and the final result of hash join is no less than impressive! Maybe I will write another blog explaining the joins.
Random knowledge:
1. In C you have to truly understand what pointer and memory (i.e. the “stuff” the pointer refers to) are. Without much systems knowledge I screwed up so many times! So what I did once was when I was passing the name of columns I read from files, I did not copy them. So it was basically that I was passing the pointers to the string. So every-time the column name got rewritten and it took me a good amount of time to figure that out.
2. void * pointer is probably the best thing about C (or maybe not…). One of the reason I loved python was you can make your functions polymorphic and deal with anything. Now with the void pointer although you might have to consider cases for different datatype, you can pass different things in a single struct! Which makes life really, really easy. For example, I had two major data structs bigarr for array based columns and node for B+tree. So in my column struct I could pass either of them by casting the pointer to a void pointer! Magic!
|
1 2 3 4 5 6 7 8 |
typedef struct { char *name; int type; // 0 = btree, 1= bigarr, sorted, 2=bigarr, unsorted, 3 = binary table (normal), // 4 = binary table (b+tree) void * object; // pointer to array or tree structure // binary table: val array/ B+tree bigarr * sec_obj; //(optional) unsorted array if b+tree // binary table: positions, }col_data; |
3. i++ vs ++i: This is most likely a very silly thing, but as we learned about the importance of writing tight loops writing something the following is necessary.
|
1 2 |
for (int i = 0; i < col->size; ++i) col->arr[col->size++] = i; |
Although I don’t really know how much that helps in terms of reducing functional stack overhead, but it is cool and compact at least! So the difference between i++ and ++i is that the former returns i and makes i=i+i, while the later returns i+i and makes i=i+1. Fancy, eh?
Performance study and final remarks:
Cumulatively I probably spent 200-300 hours on this project over the last the last three months. So it would be really disappointing to see a sub-par result. However, the column storage did not disappoint me! Because we just deal with at most 4 columns at a time, the joins in column store scales unbelievably well. The following graph shows the performance when we had N columns with 100,000 rows each and we see that when N increases PostgreSQL the most advanced row based store fails so hard! Look at this sweet graph!!!
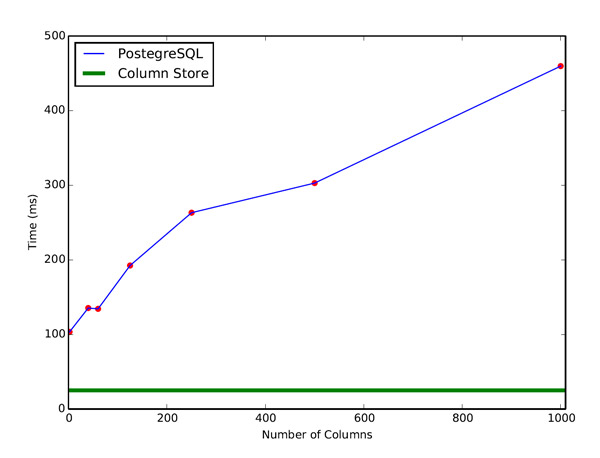
CS165 was more of an experience than a class. As I haven’t taken CS 161, I can’t comment on the comparative difficulty of these two, but hey at least I can brag about writing about 5000 lines of code and making my own database system that kicks the ass of row storage!
[I plan to keep deving the DB in future. The refactored repo can be found here: https://github.com/tmoon/TarikDB/]
Follow Me



 Welcome to my blog on education, mathematics, travel, photography, and random stuff. You can find my posts in Bangla and English separately:
Welcome to my blog on education, mathematics, travel, photography, and random stuff. You can find my posts in Bangla and English separately: