Welcome
Tag Archives: cs165
CS 165 or: How I learned to stop worrying about speed and Love the column stores
This Spring 2014 semester, I took CS 165, a course on big data database systems by Professor Stratos Idreos. This course was offered after quite a few years; so there were quite a few of us interested. However, for myself it was a course that I have been waiting for a few years to take. As I am very interested in data science and related topics, how database works under the hood is one of the basic principles I need to know before I can do any large scale analytics efficiently. Especially the slide from the first lecture sums up the necessity of learning about DBs perfectly:
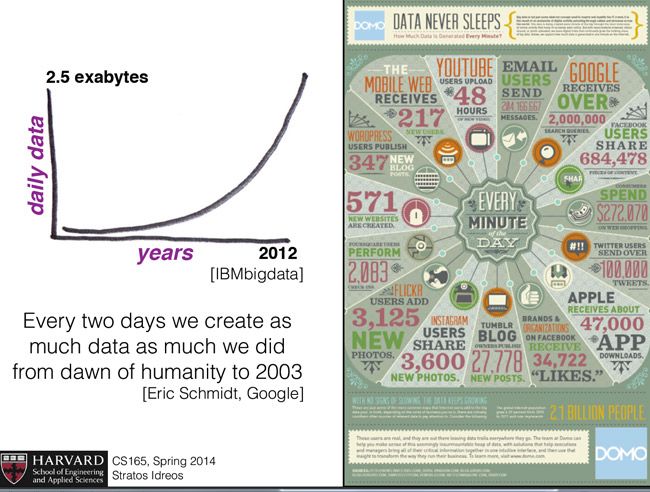
When I took the course my expectation was that this would probably be a course where we’d learn about SQL and hadoop/hive for big data. However, when I went to the office hour of Professor Idreos for the first time he said that “you don’t come to Harvard to learn about [how to code in] SQL!” So as a column storage expert, he decided to teach us about the database system in the lights of the column store paradigm.
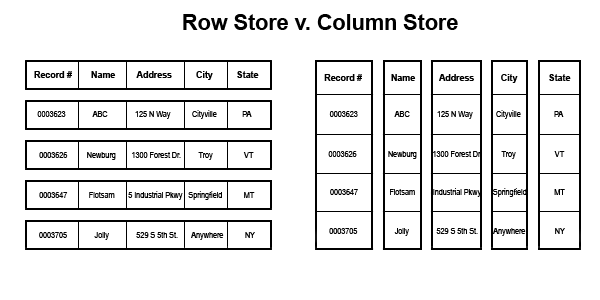
Column stores are different than the regular SQL like row stores. The store data in columns instead of rows. So when we query data the row store has to go through the whole row, whereas in column store we can just work with the specific column(s) we are interested in. This enables massive performance benefits in many cases, including scaling of the the database. I will talk about that in details in a bit.
I was excited and terrified at the same time, because having not taken any systems course (other than CS50, which does not really count) I knew that it would be really hard to make a whole working database system from scratch in C. However, I decided to stick with it. It was not easy, but I am glad I did! I feel this is one of the classes at Harvard where I learned the most. I learned how data systems work under the hood. I learned how to maintain a codebase with about 5000 lines of code. I truly learned how to use pointers and memory management. Finally I learned about low level CPU, GPU architectures and how to leverage the CPU caches to write cache conscious code. Beside these in terms I learned a lot of lessons that would pass as the big picture-take-away from the course:
Lesson 1: The real world is messy
As cliche as it might sound, the real world is too messy. It is easy to say “oh, design a database in a distributed fashion, when you have a server and client and just make the server and client send each other streams.” However, when we implement that it is a pain, to say the least. Moreover, when we get the command/data we need to parse that. Parsing strings in C is honestly no fun…or maybe I am too spoilt by Python.
Lesson 2: Sockets are neat, but painful…aargh
We have a lot of ports in our computers which we can use to communicate between computers in a network. As we had to make things distributed (i.e. many clients in a network can talk to the server) we had to make sure that the communication is actually happening. It is slightly nontrivial because at a time one computer should send message and another should listen. However, if both of them send or both of them listen, like real life, nothing productive will happen! Also the second thing I realized was that when you program your node to send it does not necessarily send the message. For example if you send 8 bytes to server, the client might not send that immediately, rather wait for more message and buffer to optimize the communication. This is a really neat and smart thing, but that means you have no control! So that kind of sucks. To get around that I had to code up a whole streaming protocol that does it correctly and that was the bane of my Spring break!
Lesson 3: B+tree…oh the black magic
If you have done any amount of CS (given you have read so far I am assuming that you have), you must have heard of the binary trees. If you had the opportunity to implement one for the first time, you probably were not the happiest person in the world. Now take that binary tree and make that more general (i.e. each node can have arbitrarily many keys). As you can probably understand, it is pretty complicated to implement a B+tree. So it was just solid 500+ lines of uncommented C code!
On the plus side, there are great advantages of B+tree. First of all, due to the structure your leafs’ keys are always sorted and you always get a balanced tree! When I saw it the first time I thought that it is black magic! However, later I realized (doing some complexity analysis) that the cost for in-memory B+tree is the same as binary tree. However, the I/O cost is significantly lower. So if you have a disk based implementation for really huge database, then it would be strictly better to use a B+tree with high order (lot of leafs).
Lesson 4: It takes a lot of hack to make something work
It is easy to throw buzzwords like distributed system, cache conscious, threaded, parallel, and so on, but it is really hard to make it work. It takes a lot of effort to make a system work and the learning curve is steep.
Especially when I was dealing with threading (to make commands from all the clients run in parallel), I realized how messed up things can get with each thread doing their own thing in parallel. And my final version is not really thread safe, but at least I understand the concept of race conditions, thread locks etc.
One hack I was particularly proud of was lazy fetching for joins. So when we make a selection and fetch, we generally have to go through different parts of the column 1+1=2 times. However, lazy fetching does not do anything in the fetch state and waits for that to happen in the join state. So I just attached the pointer to the original column (casted void!) for that and it worked really well. So in general my join would save quite a bit of work for this lazy fetching.
Lesson 5: Making things cache conscious is hard
When we have any kind of data it moves from memory (RAM) to the L1 cache of the processor which is just next to the layer of registers in a processor. So ideally you want all your data to be in L1 cache, because it takes many times more time to get data from disk/RAM compared to the L1 cache. However, L1 cache is small (something like 32KB for a core, depending on your CPU). So the best thing you can do is that to make sure when you do any computation, you don’t need to push the memory back and forth (because the CPU would push the memory back to L1 cache if it is not actively using it). So we need to make sure when we do computation with a chunk of data we do everything possible with it. This is basically the idea of cache consciousness and it is pretty hard to do this kind of optimization. So I ended up writing code like the following for loop join!

Lesson 6: Join is fascinating!
Ii is said that the most important thing invented in computer science is hashing. Although it is arguable, I know after this course that the claim is probably true. When you do join, the most naive approach is to go through each element of the second column for each element of of the first. This is clearly O(n^2). But we can do better, and sort both and do a merge sort join, which has cost O(n log n). But we can clearly do much better with hashing. We just create a hash table for the smaller column on the fly and then probe it with the elements of the bigger column and this brings it down to O(n)– the holy grail! This works really well in most cases and the final result of hash join is no less than impressive! Maybe I will write another blog explaining the joins.
Random knowledge:
1. In C you have to truly understand what pointer and memory (i.e. the “stuff” the pointer refers to) are. Without much systems knowledge I screwed up so many times! So what I did once was when I was passing the name of columns I read from files, I did not copy them. So it was basically that I was passing the pointers to the string. So every-time the column name got rewritten and it took me a good amount of time to figure that out.
2. void * pointer is probably the best thing about C (or maybe not…). One of the reason I loved python was you can make your functions polymorphic and deal with anything. Now with the void pointer although you might have to consider cases for different datatype, you can pass different things in a single struct! Which makes life really, really easy. For example, I had two major data structs bigarr for array based columns and node for B+tree. So in my column struct I could pass either of them by casting the pointer to a void pointer! Magic!
|
1 2 3 4 5 6 7 8 |
typedef struct { char *name; int type; // 0 = btree, 1= bigarr, sorted, 2=bigarr, unsorted, 3 = binary table (normal), // 4 = binary table (b+tree) void * object; // pointer to array or tree structure // binary table: val array/ B+tree bigarr * sec_obj; //(optional) unsorted array if b+tree // binary table: positions, }col_data; |
3. i++ vs ++i: This is most likely a very silly thing, but as we learned about the importance of writing tight loops writing something the following is necessary.
|
1 2 |
for (int i = 0; i < col->size; ++i) col->arr[col->size++] = i; |
Although I don’t really know how much that helps in terms of reducing functional stack overhead, but it is cool and compact at least! So the difference between i++ and ++i is that the former returns i and makes i=i+i, while the later returns i+i and makes i=i+1. Fancy, eh?
Performance study and final remarks:
Cumulatively I probably spent 200-300 hours on this project over the last the last three months. So it would be really disappointing to see a sub-par result. However, the column storage did not disappoint me! Because we just deal with at most 4 columns at a time, the joins in column store scales unbelievably well. The following graph shows the performance when we had N columns with 100,000 rows each and we see that when N increases PostgreSQL the most advanced row based store fails so hard! Look at this sweet graph!!!
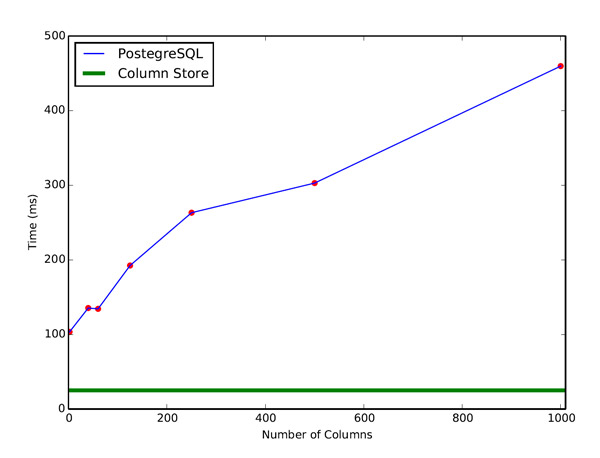
CS165 was more of an experience than a class. As I haven’t taken CS 161, I can’t comment on the comparative difficulty of these two, but hey at least I can brag about writing about 5000 lines of code and making my own database system that kicks the ass of row storage!
[I plan to keep deving the DB in future. The refactored repo can be found here: https://github.com/tmoon/TarikDB/]
Follow Me



 Welcome to my blog on education, mathematics, travel, photography, and random stuff. You can find my posts in Bangla and English separately:
Welcome to my blog on education, mathematics, travel, photography, and random stuff. You can find my posts in Bangla and English separately: