“‘Data! Data! Data!’ he cried, impatiently. ‘I can’t make bricks without clay’.”
– Sherlock Holmes (by Sir Arthur Conan Doyle, 1859-1930)
As a data scientist and machine learning researcher, I have always been fascinated by doing research on improving ways to collect, interpret, and predict data. Driven by this interest, I have worked on projects ranging from data visualization and web scraping to hardware aware machine learning and forecasting models. Here are some of the key projects that I am particularly proud of:
Turning Big Data into Small Data: Hardware Aware Approximate Clustering with Randomized SVD and Coresets
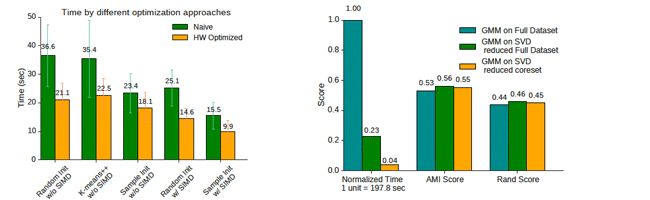
As an undergraduate researcher at Harvard DASlab, which studies how to make data systems better not only for data storage and retrieval but also for data exploration and analysis, I conducted research on gathering insights from high dimensional big data. To extend my research work, I wrote a senior thesis on optimizing machine learning algorithms such as clustering and GMM. By analyzing the pitfalls of the traditional algorithms, I was able to design hardware conscious algorithms and systems that were on average more than an order of magnitude faster than the traditional versions of those.
Bangla Pi: Affordable Computing for Everyone

Bangla Pi is an education technology project that aims at leveraging computing platforms similar to raspberry pi with cheap ARM processors to build an affordable educational tool. The core idea was to use an affordable computing platform to augment and empower the teachers. In 2015, I ran pilot projects in several schools in Bangladesh to teach basic computer programming to about 120 students from different age groups. Bangla Pi won awards at several innovation challenges including ASME Innovation Showcase and Harvard i3 Innovation Challenge.
Twouija: Visualizing Popularity of Tweets:
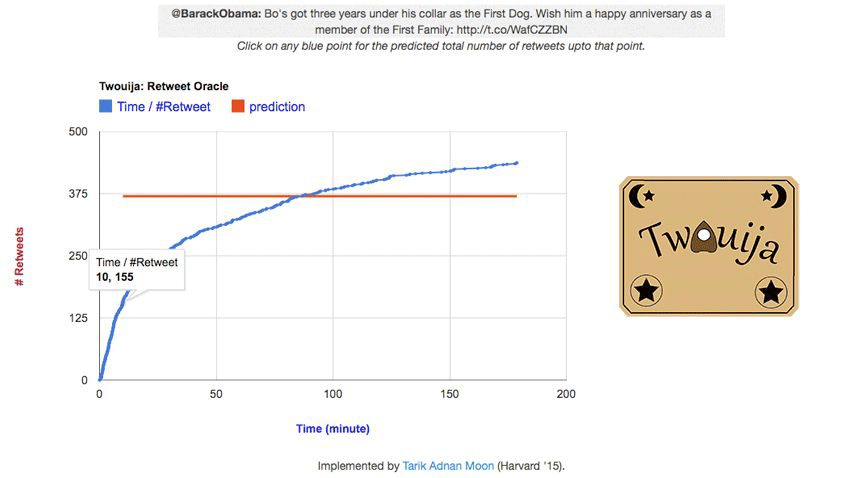
I worked with Tauhid Zaman, assistant professor at MIT Sloan School of Management to implement a visualization tool for his research on a Bayesian predictive model to forecast the popularity of tweets. In this visualization, one can see the predicted number of retweets by clicking on each point of the time series graph of retweets. The research and the visualization work were featured on major news outlets including Wired, Mashable, and PCWorld.
Mimo Baby Monitor Dashboard:
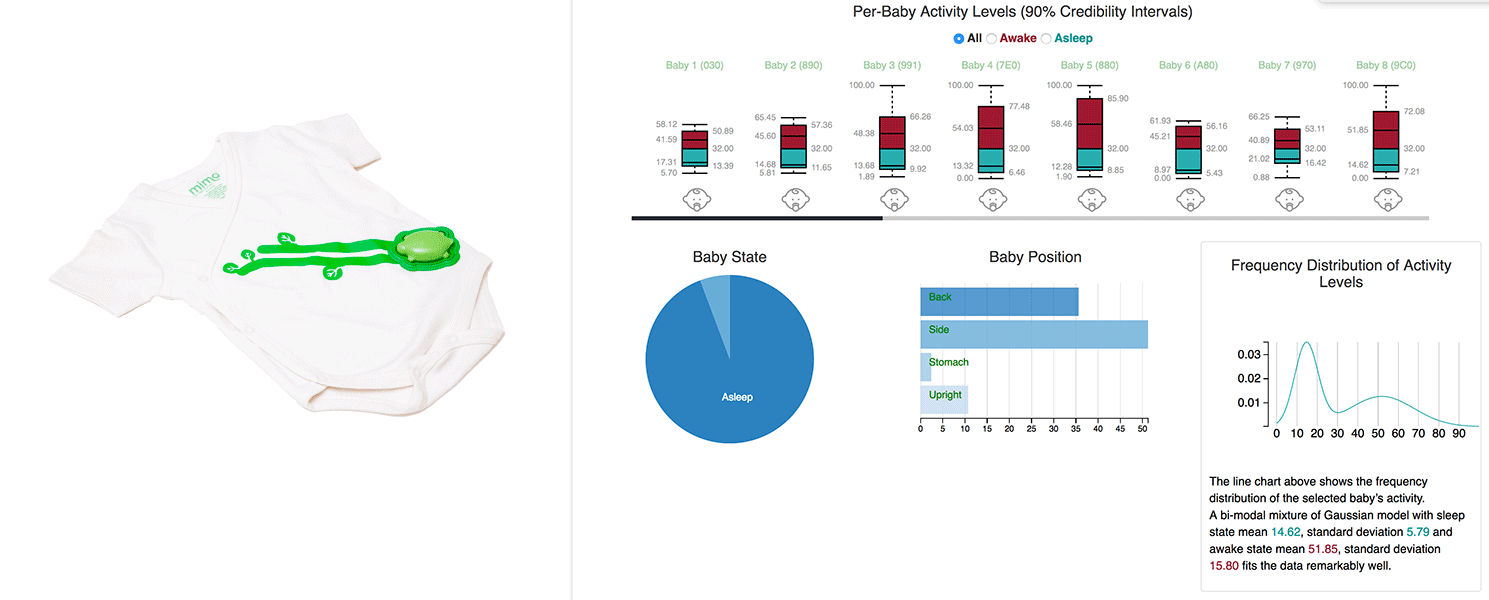
I collaborated with Rest Devices, a Boston based startup, to get anonymized data from their advanced infant activity monitor product, Mimo. Using D3 visualization library, worked to created a dashboard for them to track and visualize the activity, state, and positions of the babies. While this is a simple looking visualization, under the hood it is fairly complex visualization project because the graphs are interconnected with one another, and changing states in one graph alters the other graphs too. This started as the final project of CS 171, a data visualization course at Harvard, but later Mimo used this as a part of their product.
TarikDB: High Performance Column Storage:
This software development project started as a part of the data systems course (CS 165) at Harvard. I wrote about 4,000 lines of C code to build a performance optimized column storage that can perform all the typical operations in a data systems such as select, range query, joins, and can support advanced B+ tree index. I wrote a blog post on the lessons I learned from the class on designing and implementing a data system. The codebase for the DB can be accessed on my Github repository here.
Finding Optimal Bidding Price for eBay Auction:

In this group research project, we tried to predict the final winning bid of a car from the bidding data we collected from eBay’s auction history. It was an interesting project for me, because I had to write a distributed data scraping system that recycles through ip addresses so that eBay’s security system does not ban our data collection IP addresses.
Disclosure: The data analysis part was a group effort and I worked primarily on data scraping from eBay and the multivariate linear regression model.
Constructing 3D objects from 2D images:

This was the final project for the computer vision course. I replicated the cutting edge results in computer vision and developed a system that can create 3D model of any object (e.g. a glue bottle or a toy dinosaur) with varying degree of success! The project report is here.
Data Science Work at a Stealth Startup:
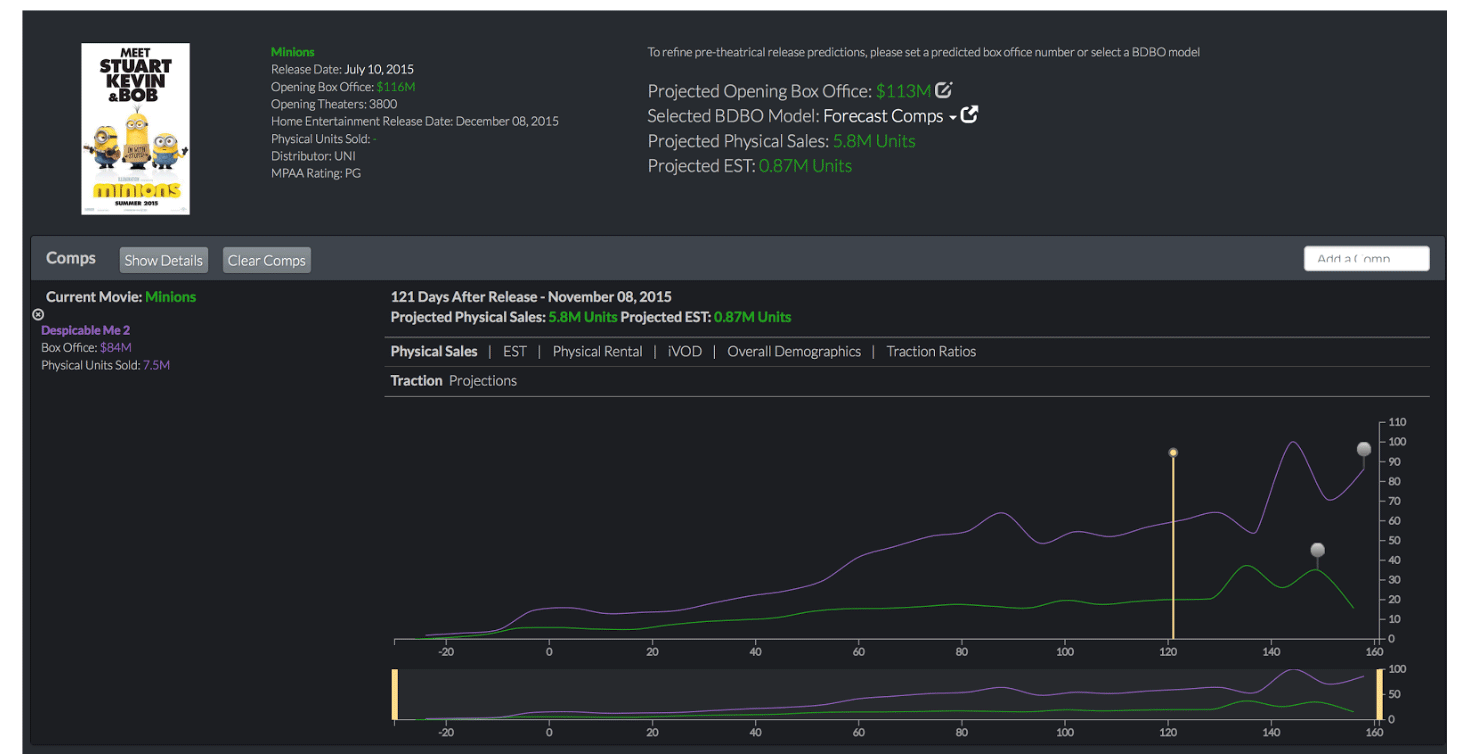
As a whole, the startup is leveraging search, social media, and popular website traffic and activity records to measure public interest regarding movies and tv shows. Using that metric, we can predict future outcomes and value different media events (including advertisements). The analytics tools we developed help the film and television studios to optimize their marketing strategies. Our data products have been proven to be vastly superior compared to the existing survey based approaches and as a result several large movie studios have signed up as our customers.
Some of the specific projects I have worked on include home entertainment sales forecasting, movie release date schedule optimizer, and television rating predictors. I have applied statistical modeling and machine learning techniques such as random forests, kernel ridge regressions, MCMC sampler, and neural networks for solving those problems.