Organizing data into groups using unsupervised learning algorithms such as k-means clustering and GMM are some of the most widely used techniques in data exploration and data mining. As these clustering algorithms are iterative by nature, for big datasets it is increasingly challenging to find clusters quickly. The iterative nature of k-means makes it inherently difficult to optimize such algorithms for modern hardware, especially as pushing data through the memory hierarchy is the main bottleneck in modern systems. Therefore, performing on-the fly unsupervised learning is particularly challenging.
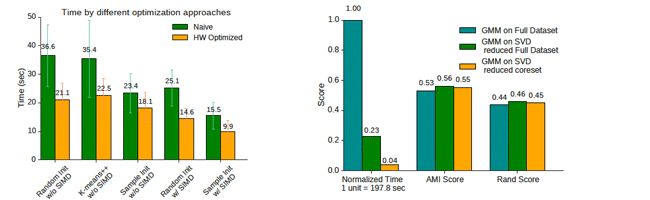
In this thesis, we address this challenge by presenting an ensemble of algorithms to provide hardware-aware clustering along with a road-map for hardware-aware machine learning algorithms. We move beyond simple yet aggressive parallelization useful only for the embarrassingly parallel parts of the algorithms by employing data reduction, re-factoring of the algorithm, as well as, parallelization through SIMD commands of a general purpose processor. We find that careful engineering employing the SIMD instructions available by the processor and hand-tuning reduces response time by about 4 times. Further, by reducing both data dimensionality and data-points by PCA and then coreset-based sampling we get a very good representative sample of the dataset.
Running clustering on the reduced dataset, we achieve a significant speedup. This data reduction technique reduces data dimensionality and data-points, effectively reducing the cost of the k-means algorithm by reducing the number of iteration and the total amount of computations. Last but not least, using this we can save pre-computed data to compute cluster variations on the fly. Compared to the state of the art using k-means++, our approach offers comparable accuracy while running about 14 times faster, by moving less data fewer times through the memory hierarchy.
The full thesis is here: Tarik-Moon-Senior-Thesis-2015